안녕하세요. 오늘은 Double Linked List에 대해 알아보고자 합니다. 우선 Double Linked List를 만들기 전에 지난 시간에 했었던 코드를 정리해보죠.
AddNode와 RemoveNode를 따로 했었는데 이거를 하나의 struct를 정의해서 그 struct안에 몰아넣도록 해줍니다.
현대 프로그래밍 언어에서는 결합성을 올리고 의존성을 내리는데요. 관련되어 있는 것들은 하나로 묶어서 하나의 모듈로 만들고, 관련 없는 것들 끼리는 서로 의존관계가 생기지 않도록 의존성을 끊는다는 의미입니다.
그래서 AddNode와 RemoveNode는 서로 관련이 있기 때문에 하나의 struct로 묶겠습니다.
type LinkedList struct {
root *Node
tail *Node
}
func (l *LinkedList) AddNode(val int) {
if l.root == nil {
l.root = &Node{val: val}
l.tail = l.root
return
}
l.tail.next = &Node{val: val}
l.tail = l.tail.next
}이런식으로 struct를 만들어주고 이 struct가 가지고 있는 메소드는 AddNode()와 RemoveNode()를 갖게 될 것 입니다.
그래서 그것을 복사해서 AddNode()를 다시 만들어 줍니다. 이 함수는 그냥 함수가 아니라 Linked List를 가지고 있는 메소드이고, tail은 가지고 있기 때문에 받을 필요 없고, Add했을 때 반환값은 필요 없기 때문에 다음과 같이 작성 합니다.
1 : 맨 처음 LinedList를 만들 당시에는 root와 tail이 nil인 상태일 것입니다. 그래서 없는 상태면 root는 노드를 하나 만들어서 새로 만든 노드의 주소를 포인터 형태로 가지고 있고, tail은 root하고 똑같기 때문에(노드가 1개기 때문에) root값을 넣어주고 반환시켜 줍니다.
2 : 만약에 root가 nil이 아닐 경우 그럴 때는 tail 뒤에 새로운 노드를 만들어서 붙여주면 됩니다.
3 : tail이 추가 되어 tail이 변경 되었기 때문에 tail을 갱신해주어야 합니다.
Add를 했으니 Remove를 만들어보죠
func (l *LinkedList) RemoveNode(node *Node) {
if node == l.root { // 1
l.root = l.root.next
node.next = nil
return
}
prev := l.root // 2
for prev.next != node {
prev = prev.next
}
if node == l.tail {
prev.next = nil
l.tail = prev
} else {
prev.next = prev.next.next
}
node.next = nil // 3
}RemoveNode는 Remove할 Node만 입력받으면 되고, 갱신 정보도 반환할 필요가 없기 때문에 위와 같이 수정해 줍니다.
1 : 노드가 l의 root와 같을 때, 맨 앞에 있는 노드를 지우려 할 때 root를 다음 노드로 바꾸어 줍니다.
현재 노드의 연결만 끊어줍니다.
2 : 노드가 tail과 같다면 맨 뒤에 것을 끊어주어야 하는데 지난 시간에 했던 코드를 가져옵니다.
3 : 노드가 지워졌기 때문에 node의 next는 nil로 바꾸어 줍니다.
그 다음 PrintNode도 만들어봅시다!
func (l *LinkedList) PrintNodes() {
node := l.root
for node.next != nil {
fmt.Printf("%d -> ", node.val)
node = node.next
}
fmt.Printf("%d\n", node.val)
}root는 이미 갖고 있기 때문에 다음과 같이 수정해 줍니다.
이렇게 바꾸면 새로운 struct를 만들었고, 이 struct가 root와 tail을 맴버 변수로 가지고 있습니다.
그리고 이 Linked List struct안에 포함된 메소드를 3개를 추가 했습니다.
이것을 사용하는 방법은 간단합니다.
func main() {
list := &LinkedList{}
list.AddNode(0)
for i := 1; i < 10; i++ {
list.AddNode(i)
}
list.PrintNodes()
list.RemoveNode(list.root.next)
list.PrintNodes()
list.RemoveNode(list.root)
list.PrintNodes()
list.RemoveNode(list.tail)
list.PrintNodes()
fmt.Printf("tail:%d\n", list.tail.val)
}지난번에는 tail과 root를 전역변수 형태로 가지고 있어야 했는데 이제 그럴 필요없이 list를 하나 만들고 LinkedList struct 주소 값을 넣어 줍니다. 그렇게 되면 그 안에 root와 tail이 포함되어 있기 때문에 따로 만들 필요가 없습니다.
그 다음에 list의 AddNode를 해서 0을 추가 해주고, 전에 했던 것처럼 1 ~ 10까지 노드를 추가해 줍니다.
그리고 list의 PrintNodes로 출력시켜주고, 지난 번에 했던 코드들을 LinkedList struct에 맞추어 수정해 줍니다.
그 다음 기존의 함수들은 필요 없기 때문에 지워주고, 실행시켜보죠.

0부터 9까지 추가를 했고, 첫번째 root의 next를 지워서 1을 없앴고, root를 없애서 0을 없어지고, tail을 없애서 9가 없어져서 2 ~ 8까지 남아있는 것을 볼 수 있습니다.
지금까지 지난번 코드들을 정리했었고, struct로 묶어서 지난번의 코드보다 훨씬 깔끔해진 것을 알 수 있습니다.
이제 Double Linked List를 만들어 볼 것인데요. Double Linked List는 지난번에 말했듯이 전에 값인 prev를 기억하고 있다고 했었죠? 그래서 LinkedList struct를 수정해 줍니다.
type LinkedList struct {
root *Node
prev *Node
tail *Node
}그 뒤 AddNode할 때 prev를 지정해주어야 합니다.
func (l *LinkedList) AddNode(val int) {
if l.root == nil {
l.root = &Node{val: val}
l.tail = l.root
return
}
l.tail.next = &Node{val: val}
prev := l.tail
l.tail = l.tail.next
l.tail.prev = prev
}prev가 기존 tail을 저장하고 있고, 새로운 tail의 prev를 기존 tail로 바꾸어 줍니다.
Remove할 때도 연결을 끊어주기 위해 prev의 정보도 날려주어야 합니다.
func (l *LinkedList) RemoveNode(node *Node) {
if node == l.root {
l.root = l.root.next
l.root.prev = nil // 1
node.next = nil
return
}
prev := node.prev // 3
if node == l.tail {
prev.next = nil
l.tail.prev = nil // 2
l.tail = prev
} else {
node.prev = nil
prev.next = prev.next.next
prev.next.prev = prev // 4
}
node.next = nil
}1 : root를 갱신 했기 때문에 root의 prev를 날려 줍니다.
2 : tail과 같으면 tail의 prev로 갱신해주는데 갱신해주기 전에 tail의 prev도 날려 줍니다.
3 : 기존과 다르게 현재 지우고자 하는 노드의 prev로 가면 되기 때문에 루트부터 시작해서 지울 값을 찾을 필요가 없어 졌습니다.
4 : 건너 뛸 때 지워주는 노드의 prev를 없애주고 건너 뛴 다음에 새로운 next의 prev를 현재 prev로 바꾸어 줍니다.
이렇게 한 뒤에 실행해보죠.

결과가 똑같은 걸 알 수 있습니다.
그리고 tail을 알고 있기 때문에 끝에서 처음으로 출력하는 것도 가능합니다.
prev node가 없었을 때는 역으로 출력이 안됐지만 prev node가 있기 때문에 역으로 출력이 가능합니다.
만들어보죠!
func (l *LinkedList) PrintReverse() {
node := l.tail
for node.prev != nil {
fmt.Printf("%d -> ", node.val)
node = node.prev
}
fmt.Printf("%d\n", node.val)
}PrintNodes()랑 똑같은데 차이가 있다면 PrintNodes()는 node.next로 전진했다면, PrintReverse()에서는 node.prev로 전진한다는 차이가 있습니다.
main()에 PrintReverse()를 추가한 뒤 실행하여 확인해보죠
func main() {
list := &LinkedList{}
list.AddNode(0)
for i := 1; i < 10; i++ {
list.AddNode(i)
}
list.PrintNodes()
list.RemoveNode(list.root.next)
list.PrintNodes()
list.RemoveNode(list.root)
list.PrintNodes()
list.RemoveNode(list.tail)
list.PrintNodes()
fmt.Printf("tail:%d\n", list.tail.val)
list.PrintReverse()
}
거꾸로 출력되는 것을 알 수 있다. 이것이 Double Linked List입니다.
여기까지 정리해보면 일반적인 Linked List는 next로 연결이 되어 있습니다. 그래서 Add를 할려면 맨 뒤에 것에 하나를 추가하면 되고, Remove할려면 그 전에 것을 찾아서 그 다음에 있는 것을 건너뛰어 버리고 중간에 있는 것을 지워버리면 됩니다.
Double Linked List는 양쪽을 다 가리키고 있고, 내 전, 다음으로 갈 수 있습니다.
추가할 때는 마찬가지로 맨 뒤에 것에 하나를 추가해주고, 링크만 제대로 맞춰주면 됩니다. 지워줄 때는 건너 뛰어 버리고 중간에 있는것을 지우는데 기존의 prev도 맞춰서 갱신해주어야 합니다.
그러면 실제적으로 Linked List, Slice하고 뭐가 틀린것인지 살펴봅시다.
Slice는 배열인데 Slice에 값이 있고
| 1 | 2 | 3 | 4 | 5 | 6 |
이제 Remove를 보자 이걸 append가 되는 경우에 Capacity와 Length가 있다고 했었는데 Capacity가 다 차면 기존 크기의 2배짜리 배열을 만든 다음에 기존 값을 복사하고, append 하는데 append 할 때 속도가 어떤지 보자 속도라는 것은 요소가 몇 개 있을 때 for문을 몇번 돌아야 되는지로 측정 합니다.
위 요소는 6개 있기 때문에 복사를 할 때 6번 for문을 돌면서 복사를 할 것입니다. 그리고 하나를 추가합니다.
그래서 이 Slice에서 append는 O(N)이라고 볼 수 있습니다. 물론 빈자리가 있으면 빈자리에 추가하면 되서 O(1)이지만 빈자리가 없을 때는 O(N) 입니다.
그래서 속도를 측정할 때는 가장 최악의 기준 값을 잡기 때문에 O(N)이라고 보면 됩니다.
반면에 Linked List는 추가할 때 현재 요소에 상관없이 맨 뒤에 하나만 넣으면 되기 때문에 그래서 추가할 때 속도는 항상 O(1)이 됩니다.
Slice에서 Remove를 할 때는 이 Remove가 어디서 일어나는지가 중요한데 맨 뒤에서 일어난다고 가정해보죠.
| 1 | 2 | 3 | 4 | 5 | 6 |
이 때 슬라이스의 요소는 위와 같고, 맨 뒤에서 일어나는 경우 Slice는 Capacity와 Length가 있다고 했었는데 지금 Capacity와 Length는 같은 상태 입니다.
둘 다 맨 끝에 차있습니다. 이 때 맨뒤에 값을 없애려고 할 때 이 때 저 슬라이스를 a라고 가정해보죠.
시작 인덱스가 0 마지막 인덱스가 5여서 a[0:5]를 사용하여 맨 뒤에 것을 빼고 나머지를 가져올 수 있는데 지난번에도 말했듯이 나머지를 복사해서 가져오는게 아니라 Length 포인터만 5번째 인덱스로 바꿔주는 것입니다.
그러면 이 때 Slice는 이 만큼만 가리키는 Slice가 되는것입니다.
| 1 | 2 | 3 | 4 | 5 |
값이 실제로 지워지지 않았지만 이 슬라이스에서는 사용되고 있지 않은 것이기 때문에 맨 마지막이 없어진 것과 같은 효과라고 보면 됩니다.
그래서 맨 마지막이 없어지는 경우는 O(1)이다. for문을 돌 필요가 없습니다.
그런데 중간에서 없어지는 경우를 보죠.
| 1 | 2 | 3 | 4 | 5 |
이렇게 있을 때 3번을 뺀다고 가정해보자 3번을 뺐을 때
| 1 | 2 | 4 | 5 |
의 형태가 되어야 합니다.
이 때는 새로운 배열을 하나 생성해서 3을 뺀 나머지만 복사합니다.
이걸 코드로 나타내려면 아래와 같이 되는데
a := []int{1,2,3,4,5}
a = append(a[0:2], a[3:]...)실제 코드로 살펴보죠.
여러개의 배열을 전부 다 가져올 때 a[3:]...로 표현 합니다.
이 구문을 자세히 살펴보면 append는 어떤 배열에 어떤 값을 추가하라는 것이고, a[0:2], a[3:]...는 a의 0 ~ 2번째까지로 length를 바꾸어 새로운 Slice를 만들고, a의 4번째 부터 끝까지 잘라서 새로 생성한 Slice를 서로 붙이라는 의미 입니다.
| 1 | 2 | 3 | 4 | 5 |
어떻게 합치냐면 Length는 2를 가리킬 것이고 Capacity는 5를 가리키고 있는 상태이기 때문에 4,5를 3에 복사시킵니다.
그러면 3이 없어지고 Length는 5를 가리킬 것입니다.
| 1 | 2 | 4 | 5 |
그래서 위와 같이 됩니다.
그랬을 때 for문을 몇번이나 돌아야 될까? 내가 복사하는 양만큼 돌 것입니다.
그래서 Slice는 맨 앞과 맨 끝에서 Remove가 진행 될 때는 O(1)이지만 중간에서 일어날 경우엔 O(N)이 됩니다.
반면에 Linked List는 Single Linked List는 앞에서부터 찾아가야 하기 때문에 O(N)인데 Double Linked List는 내가 전 노드를 알고 있기 때문에 Link만 갱신해주면 되기 때문에 O(1)입니다.
그래서 지금까지 정리해보면 Slice가 append가 O(N) Remove가 맨 끝과 맨 앞은 O(1)이지만 중간은 O(N)이고, Linked List는 append는 O(1)이고, Remove는 Single은 O(N), Double은 O(1)입니다.
이렇게 보면 슬라이스는 추가도 느리고 지울때도 느리지만 Linked List는 추가할 때도 빠르고 지울 때도 빠릅니다.
그러면 Linked List가 무조건 좋네? 라고 생각할 수 있겠지만 그렇지 않습니다.
Slice의 장점은 연속된 메모리이기 때문에 어떤 특정한 인덱스로 값을 가져오고 싶을 때 바로 가져올 수 있습니다. 시작 메모리 주소와 각 메모리 항목의 사이즈를 알고 있기 때문에
이 인덱스 * size + 시작주소 를 하면 내가 가져오고 싶은 메모리 주소가 나옵니다. 이 때는 O(1)이 됩니다.
그런데 Linked List는 내가 특정 인덱스를 가지고 오고 싶으면 내가 그 만큼 전진을 해야합니다.
만약에 내가 100만번째를 가져오고 싶으면 내가 100만번 전진해야 하죠.
그러니까 이것을 Random Access라고 하는데 고정되지 않는 특정한 위치로 항목을 접근하고 싶을 때 Slice는 O(1)이지만 Linked List는 O(N)입니다.
데이터를 저장하는 이유는 나중에 쓰고 싶어서 저장하는 건데 쓰고 싶다는 건 그 데이터를 읽겠다는 것인데 그럴 때는 Slice가 월등히 좋습니다. 또 다른 특징으로 하드웨어에 대해 잘 알아야 하는데 요리할 때 메모리는 냉장고로 비유할 수 있는데 CPU가 어떤 연산을 하고 싶을 때 냉장고에서 재료를 거내서 갖다 놓는데 갖다 놓는 장소가 캐시입니다.
이 때 내가 필요한 것만 가져오는 것이 아니라 그 근처 덩어리를 가져와서 놓습니다. 그 이유는 연산은 내가 거기서 일어난다 하더라도 그 다음 연산은 그 근방에서 일어날 확률이 높기 때문에 확률 적으로 그 근처를 가져오면 냉장고에서 물건을 꺼내는 속도를 아낄 수 있기 때문입니다.
이 부분을 잘 알아야 하는데 배열은 연속된 메모리 입니다.
| 1 | 2 | 3 | 4 | 5 |
내가 3번을 읽어서 연산하고 싶을 때 CPU입장에서는 메모리에서 저것을 꺼내서 캐시에 갖다 놓아야 합니다.
갖다 놓을 때 근방에 있는 것들을 다 가져 놓는데 그러면 3번을 연산하고 for문을 돌면서 그 다음 것을 연산한다고 가정하면 캐시에 있는것만 쓰면 되기 때문에 메모리에서 다시 읽어올 필요가 없습니다.
물론 배열도 크기가 정해져 있지 않기 때문에 캐시 범위를 넘어서면 그 다음 것을 또 가져와야 하지만 그 범위 내에서는 캐시를 다시 갱신할 필요가 없습니다.
그래서 배열은 이 캐시를 활용할 때 장점을 가지고 있습니다.
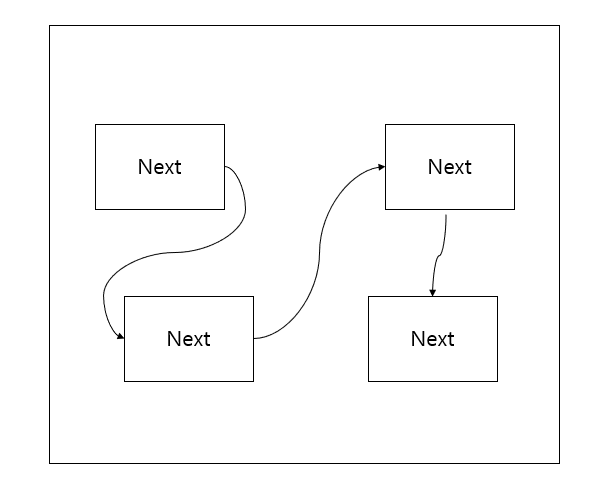
반면에 Linked List는 메모리상에 뚝뚝 떨어져 있는다고 말했었습니다. 이것을 연결하는 형태인데 이걸 가지고 연산을 하고 싶으면 CPU는 메모리에서 그 근방에 있는 것을 가져옵니다.
연산이 끝나고 그 다음 연산을 하려 할 때 다음 것은 메모리에 서로 떨어져 있기 때문에 그 근방에 있을 확률이 적죠.
그래서 가져온 캐시가 무용지물이 되어 다음 것을 가져올 때 캐시를 다 지워버리고 메모리에서 그 근방에 것을 새로 가져와야 합니다.
물론 컴퓨터는 속도가 빨라서 그렇게 하는 것은 일도 아니겠지만 이 양이 엄청나게 많아지면 문제가 됩니다.
캐시를 한번 가져온 것이 쓸모가 없어지면 캐시 미스라고 하는데 캐시 미스가 발생하게 됩니다.
그래서 배열을 쓰는 이유 중에 하나가 이 캐시미스를 최소화 하기 위해서 입니다.
이 부분을 잘 알고 있어야 합니다.
| Linked List | Slice | |
|---|---|---|
| append 할 때 속도 | O(1) | O(N) |
| Remove 할 때 속도 | O(1) | O(N) |
| 차이점 | 1. 특정 인덱스를 가지고 오고 싶으면 내가 그 만큼 전진을 해야함. 2. 캐시미스가 빈번함. |
1. 연속된 메모리이기 때문에 어떤 특정한 인덱스로 값을 가져오고 싶을 때 바로 가져올 수 있음. 2. 그 근방에 있는 것을 가져오기 때문에 캐시 미스가 적음. |
풀소스
package main
import "fmt"
type Node struct {
next *Node
prev *Node
val int
}
type LinkedList struct {
root *Node
tail *Node
}
func (l *LinkedList) AddNode(val int) {
if l.root == nil {
l.root = &Node{val: val}
l.tail = l.root
return
}
l.tail.next = &Node{val: val}
prev := l.tail
l.tail = l.tail.next
l.tail.prev = prev
}
func (l *LinkedList) RemoveNode(node *Node) {
if node == l.root {
l.root = l.root.next
l.root.prev = nil
node.next = nil
return
}
prev := node.prev
if node == l.tail {
prev.next = nil
l.tail.prev = nil
l.tail = prev
} else {
node.prev = nil
prev.next = prev.next.next
prev.next.prev = prev
}
node.next = nil
}
func (l *LinkedList) PrintNodes() {
node := l.root
for node.next != nil {
fmt.Printf("%d -> ", node.val)
node = node.next
}
fmt.Printf("%d\n", node.val)
}
func (l *LinkedList) PrintReverse() {
node := l.tail
for node.prev != nil {
fmt.Printf("%d -> ", node.val)
node = node.prev
}
fmt.Printf("%d\n", node.val)
}
func main() {
list := &LinkedList{}
list.AddNode(0)
for i := 1; i < 10; i++ {
list.AddNode(i)
}
list.PrintNodes()
list.RemoveNode(list.root.next)
list.PrintNodes()
list.RemoveNode(list.root)
list.PrintNodes()
list.RemoveNode(list.tail)
list.PrintNodes()
fmt.Printf("tail:%d\n", list.tail.val)
list.PrintReverse()
a := []int{1, 2, 3, 4, 5}
a = append(a[0:2], a[3:]...)
fmt.Println(a)
}'프로그래밍(Basic) > Golang' 카테고리의 다른 글
| [바미] Go - Tree에 대해 알아보자! (0) | 2021.01.18 |
|---|---|
| [바미] Go - Packaging 과 Stack, Queue에 대해 알아보자! (0) | 2021.01.12 |
| [바미] Go - Linked List에 대해 알아보자. (0) | 2020.12.31 |
| [바미] Go - Instance에 대해 알아보자! (0) | 2020.12.31 |
| [바미] Go - Slice를 심도있게 알아보자. (0) | 2020.12.30 |