안녕하세요! 오늘은 Map을 구현해 보도록 하겠습니다.
그 중에서 Hash Map을 직접 만들어 볼 것인데 지금 만들어볼 Hash Map은 Rolling hash인데 간단한 Hash중에 하나입니다.
"abcde"라는 String있을 때 첫 번째를 s0, 그 다음 s1, s2, s3, s4라 했을 때
a b c d e
s0 s1 s2 s3 s4(s0 * A(특정숫자) + s1) % B 한 값을 Rolling hash 라고 합니다.
다시 적어보면 s는 s0 ~ sN까지 있을 때 H(Hash의 H)i = (Hi-1 * A + si) % B가 됩니다.
예를 들어 방금
a b c d e
s0 s1 s2 s3 s4이러한 값이 있다고 했는데
이 첫번째 글자의 Hash값은 H0가 됩니다.
a b c d e
H0그럴 때 H0-1은 없으니까 H0 = (s0) % B가 되는데 s0는 문자에 해당하는 키 값 입니다.
한 문자는 1byte의 아스키 코드 값이 나오는데 0 ~ 255사이 값이 나올 것인데 거기에 % B한 값이 H0이고, H1은 위와 같이 구한 H0에 A를 곱한다음 s1을 더한 값에 B를 나머지 연산 한 값이 됩니다.
H1 = (H0 * A + s1) % B
이제 이것을 끝까지 반복하면 아래와 같이 모두 구할 수 있게 됩니다.
a b c d e
H0 H1 H2 H3 H4그래서 문자열 끝까지 다 돌렸을 때 나오는 최종 Hash값인 H4가 이 문자열의 최종 Hash값이 될 것 입니다.
이게 Rolling hash라고 부르는 이유는 한 글자 씩 굴러 가면서 만들어 낸다해서 그렇게 부릅니다.
이 때 A와 B의 숫자를 정해야 되는데 A는 보통 s값의 범위를 적어주는게 좋습니다.
그러니까 s가 문자의 값은 아스키 문자열에서 0 ~ 255사이의 값이 나오니까 A는 곱해서 들어가니까 저 값보다 큰 A = 256으로 하면 좋습니다.
이제 B는 나머지 연산을 하는건데 B값을 소수로 잡는게 좋습니다. 소수로 잡으면 값의 분포가 넓게 퍼지기 때문인데 B는 아무 소수나 상관 없는데 적당히 크고 적당히 좋은 3571을 B로 해봅시다!
B = 3571
이제 이것을 구현해 봅시다!
dataStruct 패키지에 map.go를 추가해 줍니다!
package dataStruct
func Hash(s string) int { // 1
h := 0
A := 256
B := 3571
for i :=0; i< len(s); i++ {
h = (h*A + int(s[i])) % B
}
return h
}
1 : string을 입력받고 int를 return 시켜주는 Hash함수 생성시켜 줍니다.
Hash를 뜻하는 h, A, B는 위에 써놓은 것처럼 값을 지정해주고, s의 길이만큼 h = (h * A + s[i]) % B계산을 반복 한 뒤 h를 return 시켜줍니다.
이제 이것을 실행 시켜 줄 것인데 main.go에 Hash값을 출력해보죠!
main.go
package main
import (
"fmt"
"./dataStruct"
)
func main() {
fmt.Println("abcde = ", dataStruct.Hash("abcde"))
}결과를 확인해 봅시다!

값이 2598이 나왔는데 이 숫자는 사실 의미가 없습니다. 그냥 이 문자열을 Rolling hash를 통해 돌렸을 때 나온다는 것이기 때문입니다. Hash의 조건 중 같은 값을 입력했을 때 같은 값이 나와야 하는데 두 번 넣었을 시 똑같은 값이 나오는지 확인해 봅시다!
main.go
package main
import (
"fmt"
"./dataStruct"
)
func main() {
fmt.Println("abcde = ", dataStruct.Hash("abcde"))
fmt.Println("abcde = ", dataStruct.Hash("abcde"))
}
같은 값이 나오는걸 확인 할 수 있습니다.
그러면 반대로 다른 값을 넣었을 때 다른 값이 나오는 지 확인해보죠! main.go
package main
import (
"fmt"
"./dataStruct"
)
func main() {
fmt.Println("abcde = ", dataStruct.Hash("abcde"))
fmt.Println("abcde = ", dataStruct.Hash("abcde"))
fmt.Println("abcdef = ", dataStruct.Hash("abcdef"))
}
다른 값이 나오는 것을 확인 할 수 있습니다!
또한 눈치가 빠르신 분들은 아시겠지만 B값인 3571보다는 작은 값들이 출력되고 있다는 것을 알 수 있습니다.
그러면 이 Hash를 가지고 Map을 만들어 봅시다!
현재 Hash라는 function을 하나 만들었는데 결과값은 0 ~ 3570까지 값이 나올 것입니다.
그러면 이것을 Array를 하나 만들어서 이 Array의 수를 3570개로 하여 Map을 만들 때 Array에 Key값으로 문자열이 들어오면 해당 문자열의 Hash()를 돌려서 나온 결과값을 그 값에 해당하는 Array의 Index에 Value로 저장을 하면 됩니다.
그러면 다음번에 해당 Key로 값을 조회할 때 같은 Hash가 출력되므로 해당 Index에 있는 Value를 가져오게 됩니다.
문제는 Hash가 0 ~ 3570 사이의 값이 나오는데 문자열은 입력되는 범위는 무한대라는 것입니다.
문자열의 길이도 정해져 있지 않고, 문자열 종류도 정해져 있지 않기 때문 입니다.
하지만 출력은 0 ~ 3570사이의 값입니다. 그 말은 압축한 것이라 볼 수 있죠.
정보가 손실되는 것을 말하는데 무한개의 입력이 들어왔는데 유한개의 출력이 나오기 때문 입니다.
정보가 손실되었기 때문에 다시 저 값을 가지고 복원할 수 없습니다.
Hash의 기본 기능이고, 또한 같은 입력 시 같은 값이 나오지만 다른 입력을 넣었음에도 불구하고 같은 값이 나올 수 있습니다.
이것을 Hash충돌 이라고 합니다. 예를 들어보면 우리가 전화번호부를 만들 때
김AA Hash값이 3일 때 박CC의 Hash값도 3이 될 수 있어서 Array에 김AA의 전화번호를 먼저 넣고, 나중에 박CC의 전화번호를 조회할 때 김AA의 값이 나올 수 있다는 뜻입니다.
그래서 이것을 방지해야 하는데 가장 단순하게 방지해주는 방법은 Array에 Value를 그냥 집어넣는게 아니라 Array에 각각 또다른 Array를 집어넣는 것입니다. 그래서 같은 Hash값을 갖는 Data들을 다른 Array에 집어 넣어주는 것이죠.
그래서 같은 값의 Hash가 나왔을 시 그 List를 돌면서 어떤 값의 Hash가 겹치는지 확인 후에 그것의 전화번호를 반환하도록 만들어서 충돌을 방지시켜 줍니다.
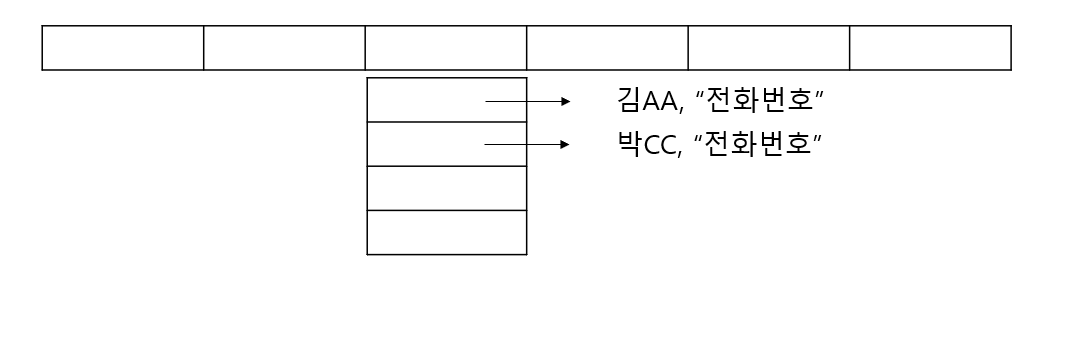
이 방법은 전체를 다시 도는 방법이랑은 다릅니다. 이것은 Hash와 같은 값만 비교하기 때문에 훨씬 비교하는 대상이 적고, 빠르게 만드는 방법이고, 이렇게 만드는 이유는 Hash의 충돌을 방지해주기 위함 입니다.
이제 코드로 구현을 해보죠!
map.go
package dataStruct
func Hash(s string) int {
h := 0
A := 256
B := 3571
for i := 0; i < len(s); i++ {
h = (h*A + int(s[i])) % B
}
return h
}
type KeyValue struct { // 1
key string
value string
}
type Map struct { // 2
keyArray [3571][]KeyValue
}
func CreateMap() *Map { // 10
return &Map{}
}
func (m * Map) Add(key, value string) { // 3
h := Hash(key) // 4
m.keyArray[h] = append(m.keyArray[h], keyValue{key, value}) // 5
}
func (m *Map) Get(key string) string { // 6
h : Hash(key) // 7
for i:=0; i< len(m.keyArray[h]); i++ { // 8
if m.keyArray[h][i].key == key { // 9
return m.keyArray[h][i].value
}
}
return ""
}
1 : KeyValue struct 생성 해줍니다.
2 : 먼저 Map이라는 struct를 생성시켜주고, 이 안에 각 hash값에 해당하는 범위인 3571개의 Array를 넣어주고, 그 Array의 항목에는 Key와 ValueList를 갖는 들어 갑니다.
3 : 그 후 Add라는 함수를 만들어서 key와 value를 입력받아 add 할 수 있게 해줍니다.
4 : 먼저 key에 해당하는 Hash값을 뽑아주고,
5 : hash에 해당하는 Index에 keyValue를 append 시켜주고, append한 결과를 m.KeyArray[h]에 넣어 줍니다.
이렇게 되면 Hash()에 key를 넣고 돌린 h라는 값에 해당하는 List가 있을텐데 그 List에 keyValue를 추가하고, 추가된 List를 다시 재정의 하는 부분으로 보면 됩니다.
6 : 이제 가져오는 key를 입력받아 value를 가져오는 Get함수를 생성해 줍니다.
7 : 마찬가지로 key에 대한 hash값을 구해주고,
8 : 이 hash값을 for문을 돌려서 이 hash값에 해당하는 list안에 key값이 있는지 확인을 해줍니다.
9 : 같은 키가 있으면 그 value를 반환해주고, 없을 경우엔 빈 문자열을 반환해 줍니다.
10 : Map의 포인터를 반환하는 CreateMap이라는 함수를 생성해 줍니다.
이제 main함수로 넘어와 기존에 있던거 놔두고 코드를 추가해 줍니다.
main.go
package main
import (
"fmt"
"./dataStruct"
)
func main() {
fmt.Println("abcde = ", dataStruct.Hash("abcde"))
fmt.Println("abcde = ", dataStruct.Hash("abcde"))
fmt.Println("abcdef = ", dataStruct.Hash("abcdef"))
fmt.Println("")
m := dataStruct.CreateMap()
m.Add("AAA", "01012345555")
m.Add("BBB", "01023456666")
m.Add("CCDASDQWEQDASD", "01011112222")
m.Add("DDD", "01775756665")
fmt.Println("AAA = ", m.Get("AAA"))
fmt.Println("BBB = ", m.Get("BBB"))
fmt.Println("DDD = ", m.Get("DDD"))
// 없는 key
fmt.Println("FFASDSAD = ", m.Get("FFASDSAD"))
}
먼저 빈 map을 만들어주고, 빈 map에 Add()를 사용하여 data를 채워준 뒤, 해당 key값을 가진 data를 조회하기 위해 Get함수에 key값을 넣어주어 조회시켜 줍니다.
마지막에 넣지 않는 key값을 조회시켜 어떤 일이 일어나는지도 살펴보죠!

넣었던 값들은 정상적으로 출력이 되고, 넣지 않은 값은 정상적으로 출력이 되지 않는 것을 알 수 있습니다.
이렇게 Map을 만들어 보았습니다!
Map은 List와 함께 보편적으로 사용되는 struct 중 하나 입니다.
Map의 장점은 key와 value형태로 되어있는 data struct에서 Find, Add, Remove가 모두 O(1)로 끝나기 때문에 속도가 빠르다는 점이고, 단점은 Hash value는 순서가 없어서 정렬된 형태로 사용할 수 없다는 점인데 어떤 입력값이 들어왔을 때 어떤 결과값이 나오는지 알 수 없기 때문에 Hash의 결과값이 정렬 되어있는 상태가 아니라는 점입니다.
그래서 Hash의 값이 작다고 해서 입력값이 작은게 아니고, 크다고 해서 큰 것이 아니기 때문에 key를 정렬되게 뽑을 수가 없습니다.
그래서 정렬 하고 싶다면 Sorted Map을 사용하면 되지만, 이 때 속도는 O(1)이 아니라 O(log2^N)이 된다는 점을 알아두어야 합니다.
이것을 외울게 아니라 왜 HashMap은 add와 Remove와 Fined가 O(1)인지, 왜 Sorted Map은 Add와 Remove와 Fined가 O(log2^N)인지 이해해야 합니다. 그러니까 원리를 알아야 하죠.
이 부분이 이해가 되지 않는다면 앞에 다 설명을 했기 때문에 다시 보는 것을 추천합니다.
간략하게 말하자면 HashMap은 Hash를 사용하기 때문에 O(1), Sorted Map은 BST를 사용하기 때문에(반절씩 버리고 가기 때문에) O(log2^N)이 됩니다.
풀소스
Map.go
package dataStruct
func Hash(s string) int {
h := 0
A := 256
B := 3571
for i := 0; i < len(s); i++ {
h = (h*A + int(s[i])) % B
}
return h
}
type keyValue struct {
key string
value string
}
type Map struct {
keyArray [3571][]keyValue
}
func CreateMap() *Map {
return &Map{}
}
func (m *Map) Add(key, value string) {
h := Hash(key)
m.keyArray[h] = append(m.keyArray[h], keyValue{key, value})
}
func (m *Map) Get(key string) string {
h := Hash(key)
for i := 0; i < len(m.keyArray[h]); i++ {
if m.keyArray[h][i].key == key {
return m.keyArray[h][i].value
}
}
return ""
}
main.go
package main
import (
"dataStruct"
"fmt"
)
func main() {
fmt.Println("abcde = ", dataStruct.Hash("abcde"))
fmt.Println("abcde = ", dataStruct.Hash("abcde"))
fmt.Println("abcdf = ", dataStruct.Hash("abcdf"))
fmt.Println("tbcde = ", dataStruct.Hash("tbcde"))
fmt.Println("abcdefdfdddfdf = ", dataStruct.Hash("abcdefdfdddfdf"))
m := dataStruct.CreateMap()
m.Add("AAA", "0107777777")
m.Add("BBB", "0108888888")
m.Add("CDEFRGTEFVDF", "0111111111")
m.Add("CCC", "017575757575")
fmt.Println("AAA = ", m.Get("AAA"))
fmt.Println("CCC = ", m.Get("CCC"))
fmt.Println("DDD = ", m.Get("DDD"))
fmt.Println("CDEFRGTEFVDF = ", m.Get("CDEFRGTEFVDF"))
}'프로그래밍(Basic) > Golang' 카테고리의 다른 글
| [바미] Go - Thread에 대해 알아보자. (0) | 2021.03.02 |
|---|---|
| [바미] Go - GoLang에서 Map을 사용하는 이유에 대해 알아보자. (0) | 2021.03.02 |
| [바미] Go - Map 과 Hash 의 관계에 대해 알아보자. (0) | 2021.02.09 |
| [바미] Go - Heap 을 이용하여 문제를 풀어보자! (0) | 2021.02.09 |
| [바미] Go - Heap에 대해 알아보자2! (0) | 2021.02.01 |