안녕하세요. 오늘은 Map과 Hash와의 관계에 대해 알아보려 합니다.
먼저 Map이라는 것은 Key - Value형태로 데이터를 저장하는 것을 말합니다.
전화번호부가 대표적인 예인데 이름은 Key - 전화번호는 Value가 됩니다.
그래서 key가 되는 이름이 김AA이고 Value가 되는 전화번호가 010-...이고, 두 번째는 김BB 전화번호가 010-..., 세번째가 김CC 전화번호가 010-...일 때
김AA - 010...
김BB - 010...
김CC - 010...이렇게 데이터가 있을 때 이것을 Map으로 가져올 때는 Key인 김AA ~ CC로 데이터를 가져오고, 데이터를 입력할 수 있습니다.
그래서 예를들어 김AA의 전화번호를 알고 싶을 때 Map이라는 data struct가 있고, 여기에 김AA의 값을 조회하면 Map은 김AA의 Value인 010...값을 내보내게 됩니다.
어떤 값을 새로 넣을 때도 Key값을 박DD Value값을 010...라고 저장을 한 뒤 마찬가지로 이 값을 조회하고 싶으면 박DD를 Key로 조회하면 입력했었던 Value값이 나오게 됩니다.
그러면 이 Map을 어떻게 만드는지 살펴보죠!
Map은 보통 Map이라고 하는데 다른말로 사전(Dictionary)라고도 할 수 있습니다.

사전을 보게 되면 단어가 나오고 그 옆에 뜻이 나오는데 단어가 Key가 되고 단어가 Value가 되기 때문입니다.
또 어떤곳에서는 Hash Table이라고도 합니다.
이것을 만들기 위해서는 Key와 Value를 저장해야하는데 어떤 Array가 있으면 그 안에 Key와 Value를 동시에 저장하는 방법입니다.
| K-V | K-V | K-V | K-V | K-V | K-V |
그랬을 때
| 김AA 010... |
김BB 010... | 김CC 010... | 박DD 010... | ... | ... |
위와 같은 형태로 Array에 저장되어 있을텐데 만약 김CC의 전화번호가 알고 싶어서 검색하면 김AA부터 하나하나씩 조회하기 때문에 조회하다가 같으면 해당 데이터를 반환하는 형태가 되는데 어떤 값을 가져올 때 모든 값을 다 비교해야하기 때문에 속도가 O(N)이 되어 가장 비효율적인 형태이며, 실제로 이렇게 만들지는 않습니다.
두번째로 좀 더 효율적인 방법인데 BST로 Map을 만드는 방식 입니다.
그렇게 되면 반절은 항상 버리고 가기 때문에 log2^N의 속도로 찾아오기 때문에 위의 방법보다는 효율적이며, 이러한 형태로 만들어진 Map을 Sorted Map(정렬된 Map)이라고 부릅니다. 또는 Ordered Map(순서가 있는 Map)이라고도 합니다.
지금 우리가 알아볼 Map은 Hash를 사용한 Map인데 Hash라는 것은 쉽게 설명하자면 예를 들면 "김AA"라는 애가 있고,
그리고 Hash라는 function이 있을 때 Hash에 입력을 집어넣으면 어떤 출력이 나오는데 "김AA"라는 입력값을 Hash에 집어 넣으면 출력값이 항상 3이 나오고, "김BB"를 Hash에 집어넣으면 출력 값이 항상 5가 나오고, "김CC"를 집어넣으면 출력값이 항상 1이 나오고, 그러면 이 Hash라는 함수는 같은 값을 집어 넣으면 항상 같은 값이 나오는데 그 값이 1 ~ 10사이의 값을 반환하는 식으로
서로 다른 입력을 집어넣으면 서로 다른 값이 출력된다고 가정해보죠.
그랬을 때 1 ~ 10까지 값이 나오고, 같은 입력을 넣으면 같은 결과(출력)가 나오고, 다른 입력을 넣으면 다른 결과(출력)가 나온다고 가정해 보겠습니다.
이럴 때 우리는 10개를 갖는 Array를 만들 수 있고, 각 항목마다 값들을 아래와 같이 저장하게 될 것 입니다.
| 010... | 010... | 010... | 010... | 010... | 010... | 010... | 010... | 010... | 010... |
여기서 김AA라는 값을 넣었을 때 3이 나왔기 때문에 우리는 여기서 3번째 항목의 값이 김AA의 값이라는 것을 가정 할 수 있게 됩니다. 그래서 3번째 값을 가져오게 됩니다.
이렇게 함수를 이용해서 만든 Map을 HashMap이라고 합니다.
그러면 속도는 어떻게 될까요? 어떤 값을 넣어서 나온 결과에 해당하는 것을 바로 반환하기 때문에 Hash를 어떻게 만드느냐에 따라 속도를 결정합니다.
여기서 가정해야 할 것은 이 때 Hash가 돌아가는 속도는 상수입니다. 즉, 어떤 일정한 시간이 걸린다고 가정해보죠.
그렇게 되면 어떤 값을 집어넣어서 일정한 시간을 거쳐서 어떤값이 나오고 그 값에 해당하는 배열을 바로 반환하면 되기 때문에 이 때는 O(1)의 시간이 걸린다고 표현 합니다.
상수 타임이 걸린다는 의미입니다. 이 속도는 알고리즘에서는 일정한 시간, 한 번 걸린다, 시간이 거의 걸리지 않는다. 라고 말을 합니다.
왜 그러냐면 (1)은 상수 타임인데 N(갯수)가 아무리 늘어나도 속도가 일정하기 때문에 N과의 상관관계가 없기 때문에 시간이 거의 걸리지 않는다. 라고 볼 수 있는 것입니다.
이것의 관건은 이 Hash를 어떻게 만드느냐에 따라 달려있습니다.
Hash 의 필수 조건은
- 출력값의 범위가 정해져 있습니다.
- 0 ~ 99 일 수 있고, 100개 일 수도있고, 1000, 10000개 일 수 있습니다.
- 같은 입력값이면 같은 출력이 나옵니다.
- 다른 입력값이면 다른 출력이 나옵니다.
- 여기서 다른 출력이 나온다는 것은 조금 어려운 문제이기 때문에 필수 조건이라기 보다 보통 그렇다, 그런 경우가 대부분이다.라고 보면 됩니다.
그럼 이것을 어떻게 만드는지 생각해보죠. 우리가 Function을 배울 때 아래와 같이 배운적이 있을 것입니다.

이런식으로 2를 집어넣으면 4가 나오고 4를 집어 넣으면 8이 나오는 식의 함수를 선언할 수 있게 되는데
위와 같이 X2를 해주는 함수가 있다 했을 때 이 함수가 Hash 함수 조건에 만족하는지 안하는지 확인해보죠.
같은 입력값을 넣으면 같은 입력값이 나옵니다. 예를 들어 2를 넣으면 항상 4가 나오고, 4를 넣으면 항상 8이 나오죠.
그리고 다른 입력값을 넣으면 항상 다른 입력값이 나옵니다. 하지만 문제는 값의 출력값의 범위가 한정되어 있지 않는다는 점이죠.
넣을 수 있는 입력값의 수는 무한대(∞)이고, 나올 수 있는 출력 값의 수도 무한대(∞)입니다.
그렇다면 출력의 범위가 정해져 있는 값은 어떻게 만들어야 할까요?
삼각함수인 SinΘ를 생각해봅시다. 이 값은 아래와 같습니다.

0˚일 때 0이고, 90˚일 때 1이고, 180˚일 때 0이고, 270˚일 때 -1이고, 360˚일 때 0입니다.
이걸 보면 값의 범위가 -1 ~ 1로 나오고, 입력값이 360까지지만 끝에 계속 반복하고 있기 때문에 입력값이 무한대(∞)여도 출력값은 -1 ~ 1이 나옵니다. 그리고 다른값을 넣어도 보통 다른값이 나옵니다. 90˚일 때 1이 나오지만 45˚일 때 1/2이 나옵니다.
그래서 이 것은 Hash 함수가 가져야 될 조건을 만족한다고 볼 수 있습니다.
다른 함수도 알아볼까요? 나머지연산(Modular)을 봅시다. 어떤 값을 나누고 남은 나머지를 나타내는 연산이고, Golang에서는 '%'로 쓰입니다.
예를 들자면 13 % 12는 12를 13으로 나눈 나머지 값인 1이 되고, 14 % 12는 12를 14로 나눈 2가 됩니다.
이것을 그래프로 보게 되면 아래와 같은데
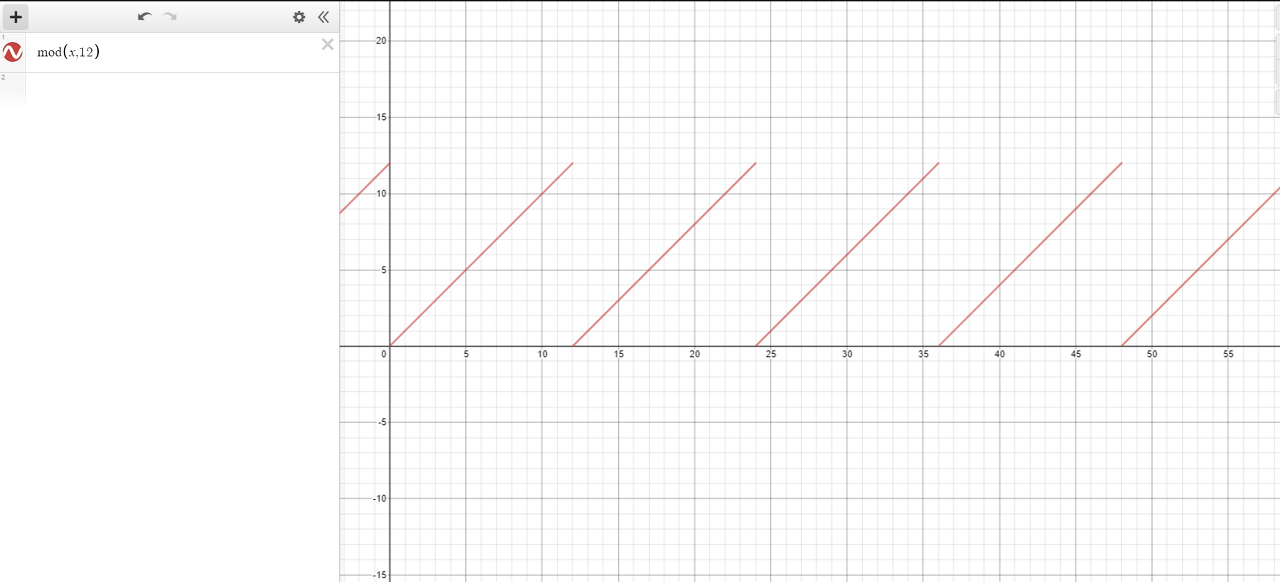
12에서 값이 0, 11에서 11 형태로 값이 반복되는 것을 알 수 있습니다.
즉, 출력값은 0 ~ 11로 반복되고, 같은 값을 넣어도 같은 값이 출력되고, 다른 값을 입력하더라도 다른 값이 출력되고, 무한대(∞)의 입력값을 넣더라도 0 ~ 11의 범위가 있기 때문에 이 것도 Hash함수의 조건에 만족한다고 볼 수 있습니다.
그런데 SinΘ를 보게 되면 값이 -1 ~ 1의 실수가 나옵니다. 정수를 넣어도 실수가 나오지만 Modular의 경우 정수를 넣으면 0~(N-1)사이의 정수가 나오게 되죠.
그리고 SinΘ은 이차함수기 때문에 계산이 복잡하지만 Modular의 경우 일차 함수이고, 나누고 나눈 값이기 때문에 계산이 빠릅니다.
그래서 보통 Hash라 할 때는 Modular를 많이 사용 합니다.
| SinΘ | Modular | |
|---|---|---|
| 출력값 범위 | -1 ~ 1 | 0 ~ (N-1) |
| 입력값 갯수 | ∞ | ∞ |
| 차이점 | 1. 정수를 입력할 때 출력 값은 실수가 나오기도 한다. 2. 이차함수 3. 계산이 복잡하다. |
1. 정수를 입력하면 정수가 나온다. 2. 일차함수 3. 계산이 빠르다. |
Modular와 같은 함수들을 One-Way Function이라고 합니다. 이것의 뜻은 한번 가면 돌아 올 수 없는 함수, 일반통행이라는 의미인데요.
어떤 x라는 값을 Modular함수인 mod()를 통해 mod(12) 결과가 3이 나왔다고 쳐봅시다.
그랬을 때 이거 가지고 12라는 숫자와 3이라는 숫자를 가지고 다시 x를 찾아내기가 어렵죠.
그 이유는 mod 12를 해서 3이 나오는 경우는 3, 15, 27, ... 등등 무한대로 존재하기 때문에 x를 유추해내기가 어렵습니다.
가령 X3이라는 함수를 가지고 χ * 3 = 9를 했을 때 3과 9의 값을 가지고 χ는 3이라는 것을 금방 유추해 낼 수 있습니다.
그 이유는 One-Way가 아니라 Two-Way이기 때문이죠.
χ * 3에서 * 3에 해당하는 연산자는 '/' 이기 때문에 3을 양변에 나눠 버리면 3이 나오기 때문에 χ는 3이라는 것을 알아 낼 수있습니다.
하지만 Modular연산은 그렇지 않습니다.
χ Mod N = M일 때 다시 이 χ가 무엇인지 N과 M을 가지고 알아내기가 어렵다. 무한개의 후보가 존재하기 때문입니다.
sin함수도 마찬가지 입니다.
45˚일 때 1/2이기도 하지만 135˚일 때도 1/2입니다. 이런식으로 무한대의 값이 존재하게 됩니다.
sin함수도 One-Way Function이라 볼 수 있지만 Hash는 Modular를 많이 사용합니다.
이게 중요한 이유는 이거 덕에 암호화를 할 수 있기 때문입니다.
우리가 어떤 사이트에 ID, PW를 입력하게 되는데 이 Pw가 만약에 "abcd"였다고 쳐봅시다.
그 때 DataBase에 그대로 "abcd"값이 저장 되었다고 했을 때 이 DB가 유출 될 경우 그 사람의 비밀번호를 알아낼 수 있게 됩니다.
옛날에는 이런식으로 되어 있어서 DB가 해킹이 되면 사람들의 비밀번호를 모두 알 수 있었지만 이것을 Hash함수를 사용하여 "abcd"의 값이 21324564879와 같은 이상한 숫자들이 나온다고 가정하게 되면 21324564879를 기억하고 있으면 "abcd"를 기억하고 있지 않아도 비밀번호 검사를 할 수 있습니다.
같은 입력을 하게 되면 같은 결과가 나오기 때문입니다.
그런데 이 숫자를 가지고 다시 "abcd"를 만들어 내기는 굉장히 어렵습니다. 이 숫자값이 나올 수 있는 입력값은 "abcd"외에도 다른 입력값들이 많이 존재하기 때문입니다.
그래서 처음 회원이 입력했던 비밀번호의 Hash값만 가지고 있으면 다음 로그인 할 때 그 비밀번호를 그대로 넘기는게 아니라 입력한 Hash값만 넘겨주어 그 두개끼리 비교하여 같으면 같은 암호라고 할 수 있습니다.
이런식으로 Hash는 여러방면에 쓰이고 있는데 공개키 암호화 방식이나 네트워크 무결성을 체크하는 checksum, 또는 요즘에 핫한 블록체인 등 많은 곳에서 Hash함수가 많이 쓰이고 있고, 종류도 다양합니다.
'프로그래밍(Basic) > Golang' 카테고리의 다른 글
| [바미] Go - GoLang에서 Map을 사용하는 이유에 대해 알아보자. (0) | 2021.03.02 |
|---|---|
| [바미] Go - Map 구현을 해보자! (0) | 2021.03.02 |
| [바미] Go - Heap 을 이용하여 문제를 풀어보자! (0) | 2021.02.09 |
| [바미] Go - Heap에 대해 알아보자2! (0) | 2021.02.01 |
| [바미] Go - Heap에 대해 알아보자! (0) | 2021.02.01 |