OOP가 나온지 20년이 되었고, 모든 개발자들이 OOP란 개념은 필수가 되었고, OOP를 해야만 하는 언어들도 많이 나타났습니다.
그 만큼 OOP는 훌륭한 개념이고, 프로그래밍 역사상 가장 훌륭한 기술이자, 가장 성공한 기술이 아닐까 싶습니다.
그럼에도 불구하고, OOP는 문제점이 점점 드러나기 시작했는데 잘 하면 좋은데 잘 하기 어렵다.는 점이죠.
이걸 잘하려면 알아야 하는 내용도 너무 많고, 숙지하고, 숙달해야 하는 부분이 너무 많기 때문이죠.
이게 단순히 지식 만으로 되지 않습니다. 이 지식을 가지고 숙달하는 과정이 필요하죠.
이 지식도 올바른 지식을 가지고 올바르게 숙달시켜야 하는데 실제 상황에서는 올바른 지식을 가진 개발자가 흔하지 않을 뿐더러 올바르게 숙달시킨 개발자도 흔치 않습니다.
그 이유는 여러가지가 있는데 현실과 마감이라는 벽에 걸리기 때문에 개발자가 충분한 시간을 가지고 연습을 할 기회가 많지 않습니다. 학생 때는 더더욱 없죠. 만약에 올바른 지식과 올바르게 숙달한 개발자가 OOP를 짜면 굉장히 좋습니다.
그렇게 성공한 프로그램들도 많죠.
하지만 문제는 프로그램이 항상 변경을 하며 발전을 한다는 점입니다. 그리고 이 프로그램을 만든 개발자는 바뀌게 됩니다.
그 말은 이직을 한다는 소리인데 처음에 좋은 프로그램을 만들었던 사람이 계속 남아 있는 것이 아니라 새로운 개발자가 그 프로그램을 담당할텐데 새로 들어온 개발자가 좋은 개발자가 아닌 경우 또는 마감에 쫓길 경우 기존에 만들었던 OOP의 구조를 흔들어 놓을 수 있고, 그 프로그램의 구조가 좋은 OOP 프로그램일 경우 그것을 파악하는 데까지 걸리는 시간이 오래 걸리게 됩니다.
그 이유는 OOP는 오브젝트 중심이기 때문에 class의 갯수가 상당히 많을 것입니다.
그랬을 경우 새로운 개발자가 기존에 만들어진 프로그램의 모든 객체의 역할과 관계를 한번에 파악하기는 불가능하기 때문입니다.
그래서 결론적으로
잘 만들기 어렵고, 잘 만들었을 때 잘 만들어진 프로그램을 새로 들어온 개발자가 파악하는데 시간이 오래 걸립니다.
그 얘기는 회사 입장에서 보면 개발자를 새로 뽑더라도 그것을 파악하는데 시간이 오래 걸리고, 바로 쓰지 못한다는 것이죠.
이게 현대에 와서 문제점이 대두되기 시작 했는데 실리콘 밸리에 대변되는 벤처 열풍이 불었는데 이 때의 모토가
Make fast
break things입니다.
제품을 시장에 빨리 내놓고, 아니다 싶으면 빨리 없애서 다른것으로 빨리 만들자는 의미이죠.
그래서 프로그램을 빨리 만들어야 하는 상황이 되었는데 OOP로는 빨리 만들기가 쉽지 않고, OOP로 빨리 만들려면 설계 원칙이 많이 깨져야 합니다.
이것을 Tech Debp이라고 하고, 번역하면 기술 부채(빚)인데 지금 이 순간에 빨리 만들어야 하기 때문에 어쩔 수 없이 빨리 엉망인 코드를 집어 넣는 것을 기술 부채라고 합니다.
그래서 OOP 프로그램에서 빨리 만들기 위해서는 이 기술 부채를 많이 쌓아야 하고, 쌓일 수 밖에 없습니다.
문제는 기술 부채를 많이 쌓아서 OOP로도 빨리 만들 수 있는데(엉망 진창으로..) 문제는 그 제품이 성공 했을 경우 펑!하고 터진다는 것이죠.
기반이 잘 되어 있지 않으면 터졌을 때 견딜 수가 없습니다. 고객은 막 들어오는데 그 고객들을 받아 줄 수 없게 되는 것입니다.
그랬을 때 빠르게 만들기 위해서 쌓아놨던 기술 부채를 최대한 빨리 없애서 그 다음 Stage로 나아가야 합니다.
고객을 계속 받아드릴 수 있는 튼튼한 구조를 만드는 쪽으로 나아가야 합니다.
하지만 성공의 확률이 낮기 때문에 처음에 제품을 만들 때 Next를 생각하고 만들 수가 없죠.
그래서 관건은 빨리 만들고, 기술 부채를 덜 지자는 것입니다.
그래서 빨리 만들되 기술 부채를 덜 지고 갈 구조가 필요하게 되는데 OOP는 여기에 맞지 않습니다.
빨리 만드는데도 맞지 않고, 기술 부채를 덜 지는데에도 맞지 않게 됩니다.
왜냐면 다루기 힘들기 때문입니다. 그래서 이러한 문제가 있기 때문에 이를 개선하기 위해서 나타난 것들이 생겨났습니다.
절차적 프로그래밍으로 시작해서 그 다음인 OOP가 왔고, 그 다음은 정해진건 없지만 정해보자면 Stateless입니다.
'상태 없음'을 의미하는데 이거에 대해 설명해보자면 이전의 절차적 프로그래밍과 OOP방식이 빠르게 만들지 못했고,
기술 부채가 많이 쌓였던 이유(변경 사항이 생겼을 때 빠르게 변경하지 못했던 이유)는 상태와 기능이 혼재되어 있었기 때문입니다.
절차적 프로그래밍에서 상태와 기능이 분리되어 있었던 것이 OOP로 가면서 합쳐졌다고 했었는데
절차적 프로그래밍에서는 상태와 기능이 분리 되어 있었기 때문에 혼재되어 있다는 말은 아니지 않냐?고
의문이 들 수 있습니다.
절차적 프로그래밍 방법으로 Sandwitch를 만들었을 때 코드를 자세히 보면 상태와 기능이 혼재되어 있다는 것을
알 수 있습니다.
package main
func main() {
// 1. 빵 두개를 꺼낸다.
breads := GetBreads(2)
// 2. 딸기잼 뚜껑을 연다.
OpenStrawberryJam(jam)
// 3. 딸기잼을 한 스푼 퍼서 빵위에 올린다.
spoon := GetOneSpoon(jam)
// 4. 딸기잼을 잘 바른다.
PutJamOnBread(breads[0], spoon)
// 5. 빵을 덮는다.
sandwitch := MakeSandwitch(breads)
// 6. 완성.
fmt.Println(sandwitch)
}보게 되면 breads은 상태이고, GetBreads(2)은 기능입니다.
그래서 상태와 기능들이 위와 같이 혼용되어 있다는 것을 알 수 있죠. (같은 소스 안에 같이 있다는 의미입니다.)
이렇기 때문에 상태와 기능이 서로 엇갈리게 됩니다.
그래서 사람들이 빠르게 못만드는 이유는 상태와 기능이 혼재되어 있기 때문이고, 상태와 기능을 완전히 분리시켜야 빠르게 개발할 수 있다는 것이죠.
모든 프로그래밍에서 발전과정을 보면 결국에 가는 과정은 레고 방식(조립 방식)입니다.
회사 입장에서 지금의 프로그래밍을 봤을 때 굉장히 방대해 졌습니다. 그 전에는 천재 프로그래머 한 두명이 코딩을 하던 시절이였다면 지금은 100명 이상의 개발자가 하나의 프로젝트에 달려들어서 프로그래밍 하는 시대가 왔기 때문입니다.
그랬을 때 이 100명 모두가 퀄리티를 다 만족 시킬 수 없습니다. 실력은 다 들쑥 날쑥하기 때문이죠.(어느 정도 맞추겠지만)
이 퀄리티를 어느정도 수준으로 유지 할 수 있는 가장 좋은 방법은 '조립 방법'입니다.
각 개발자들이 자기가 맡은 분야에서만 작업하는 것인데, 자기가 맡은 모듈에서만 그것을 넘기면 알아서 조립되서 작동할 수 있는 구조를 만들어야 많은 개발자들이 달려 들어서 빠르게 다량으로 만들 수 있는 것이죠.
또한 그 부분만 건드릴 수 있고, 그 외에 부분은 건드릴 수 없는 구조로 만들어야 조립이 원활하게 되고, 빠르게 만들 수 있고, 기술 부채도 덜 쌓이게 됩니다.
그러면 이 것을 어떻게 만들 수 있을까?가 관건이였는데 지금의 방향은 Stateless입니다.
아예 상태는 없애고, 기능만 만들자는 것인데요. 개발자는 기능만 만들고, 상태는 외부에서 가져와서 들어 갈 수 있도록 만들자는 의미입니다.
그래서 나온게 Micro Service, Serverless, Functonal language인데 Functonal language는 예전 부터 있었던 개념인데 요즘에 Stateless로 가면서 다시 각광 받기 시작했습니다.
그리고 게임 쪽에서는 ECS구조, 웹쪽에선 MVC, MVVC 등이 있습니다.
이렇게 다양하게 있지만 결국에 지향하는 것은 Stateless라는 것입니다. 분야는 서로 다르지만 같은 것을 향해 가고 있는 셈이죠.
그러면 개발자들은 상태가 분리 되어 있기 때문에 상태를 건드릴 필요가 없습니다. 상태와 기능이 혼재되어 다른 사람의 상태를 건드려서 문제가 되는 것인데 아예 기능만 만들어 놓으면 상태를 건드릴 필요가 없기 때문에 서로의 영역을 침범하지 않아도 자기가 맡은 부분을 만들어 놓기만 하면 되는 것입니다.
그리고 기능을 조립해서 만드는 방식이기 때문에 어떤 문제가 생길 때 그 기능만 분리해서 고치거나, 빼버리거나 새로 추가하면 됩니다.
이제 Functional Language에 대해 얘기해보죠. 대표적으로 Erlang, lisp, Scala, F#가 있고, 요즘에는 엘릭서라는 언어도 있습니다.
Functional Language가 무엇이냐면 함수 중심의 코딩 방식인데 우리가 함수를 얘기할 때 어떤 입력값을 넣었을 때 어떤 처리를 해서 결과가 나오게 되는데
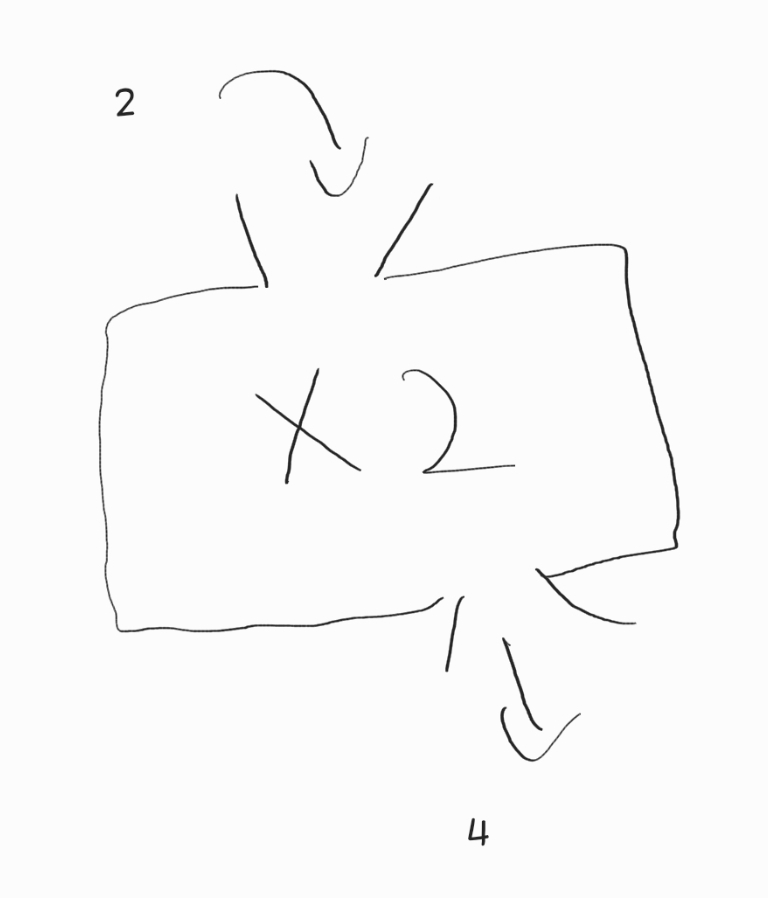
그랬을 때 입력이 같으면 출력도 같게 됩니다. 항상 1을 넣을 때마다 2가 되고, 2를 넣을 때마다 4가 되고, 3을 넣을 때마다 6이 되죠.
그 이유는 X2를 담당하는 함수가 상태 없이 순수하게 기능만 갖고 있기 때문 입니다.
그런데 우리가 코딩할 땐 같은 입력에 같은 출력이 나오게 되지 않죠.
예를 들어
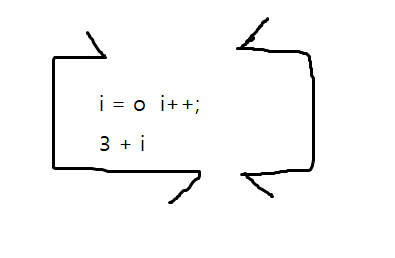
i가 0이고, i++해서 입력값 + 3 + i 한 값이 출력되는 함수가 있다고 가정해 봅시다.
그랬을 때 처음에 2를 넣으면 i는 0이였다가 i++를 하면서 1이 되고, 2 + 3 + 1을 하니까 6이 나오고, 두 번째 2를 넣으면 2 + 3 + 2가 되니까 7이 나오게 됩니다. 세 번째 2를 넣으면 8이 출력되죠.
이렇게 같은 입력을 넣었을 때 다른 출력이 나오게 되는데 이 함수가 상태를 가지고 있기 때문 입니다.
그래서 기능만 순수하게 가져가고 상태를 없애버리는 게 Functional Language이고, 이게 Stateless이죠.
그래서 이 방향으로 나아가고 있기 때문에 Functional Language가 각광받기 시작했습니다.
나온지는 오래 됐고, 기존에는 학계에서만 조금 사용하고 있었다가 최근 들어서 각광받기 시작했지요.
Micro Service도 마찬가지 입니다.
Micro Service는 어떤 웹페이지를 본다고 했을 때 어떤 TopView가 있고, 메일이 있고, 뉴스가 있고, 광고창이 있을 것이고, 로그인창 등 많은 구조들이 있을 것인데 각각을 따로 서비스로 만들어서 그것을 조합해서 한 페이지를 구성하자는 의미 입니다.
하나의 페이지도 여러 파트로 나누고, 각 파트도 여러개의 서비스를 호출해서 가져오도록 하자는 것이죠.
그랬을 때 메일에서 호출하는 서비스와 로그인에서 호출하는 서비스의 일부가 겹칠 수 있는데 그것이 상관없게 됩니다.
만약에 100개의 서비스가 있다 가정하면 웹 페이지를 만들 때 광고창 부분에서 일부분 가져오고, 메일 부분에서 일부분 가져오고, 뉴스에서 일부분 가져오면 됩니다.
그러니까 서비스 개발자들은 서비스들만 늘려나가면 되는 것이고, 웹 페이지 만드는 개발자는 만든 서비스만 가져와 쓰면 됩니다.
이런식으로 서비스를 계속 많이 만들고 조합해서 하나의 서비스를 만드는 것이 Micro Service입니다.
Serverless는 '서버가 없다.'는 의미인데
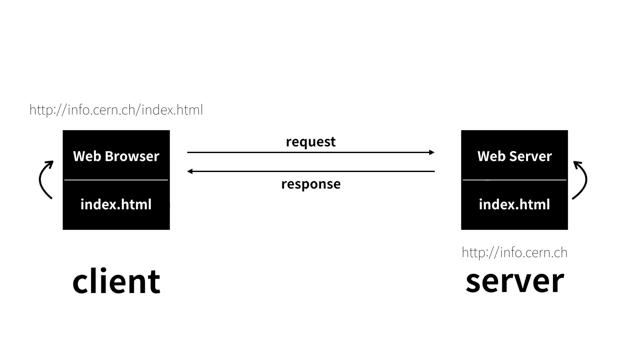
고전적인 방식에서 웹 프로그램에서 보았을 때 웹 서버가 있어서 사용자가 웹 브라우져에 주소를 쳐서 웹 서버에 요청을 하면 웹 서버가 웹 페이지를 만들어서 사용자에게 알려주는 방식이 고전적인 방식인데 게임도 마찬가지로 사용자가 게임에 접속하면 게임의 서버에서 서비스를 주고 받는 방식이 'Server방식'이였다면
이것도 Micro Service와 비슷한데 여러 서버들로 작게 작게 나누어서 웹 페이지에서 여러개의 서버들을 취합해서
사용하자는 것입니다.
웹 페이지 입장에서는 서버가 굉장히 많을 수 있게 되고, 그 중에 취합을 해서 서비스를 받자는 것입니다.
Micro Service와 같은 것이라 생각해도 무방하죠. 그리고 ECS 방식은 Entity Component System의 약자인데 게임쪽에서 나온 개념입니다.
여기서 Entity는 Component의 모음입니다. Component만 가지고 있는 것을 의미하는데 예를 들면 Player라는 Entity가 있고, 이 Entity가 가지고 있는 Component는 Move, Attack, Talk라고 했을 때 이 Component들을 모아 놓은 게 Entity 입니다.
그래서 Entity라는 것은 Player가 될 수 있고, Monster가 될 수 있고, 뭐든지 될 수 있는데 이 Entity는 어떤 Component들을 가지고 있느냐에 따라 Entity의 성격이 결정되는데 Player가 될 수 있고, NPC가 될 수 있고, Monster가 될 수 있습니다.
예를 들면 Player Entity같은 경우엔 사용자의 입력을 받아야 하기 때문에 사용자의 Input Component를 가지고 있다면 Player가 되는 것이고, Player와 같은 Entity인데 사용자의 Input을 가지고 있는게 아니라 AI를 가지고 있다면 NPC가 되는 것이죠.
이 처럼 어떤 Component를 모았냐에 따라 성격이 결정 되는 것인데 문제는 Component는 Data만 가지고 있어야 하고, System이 기능을 가지고 있어야 합니다.
이렇게 될 경우 Data의 집적도가 높아져서 성능을 올릴 수 있는 계기가 되고, 상태와 기능이 분리되어 있기 때문에
OOP의 단점을 해결 할 수 있습니다.
MVC는 Model–View–Controller인데 Model은 그냥 Data라 보면 되고, View는 화면에 어떻게 뿌려줄 것인가? Controller는 기능이라 보면 됩니다.
그래서 Data와 View와 기능을 다 분리해서 만들자는 개념인데 Data를 따로 모으고, Controller인 기능도 따로 모아놓고 View에서 이것들을 조합하여 사용하자는 것이며, 서로간의 종속성을 끊자는 의미입니다.
더 나아가서 MVVC도 있는데 이건 스킵하겠습니다.
그래서 지금은 이런 흐름으로 나아가고 있다는 것만 알아두면 됩니다. 각 분야에서 각자 흘러가는 방향이죠.
OOP에서 Stateless로 넘어가고 있고, 이렇게 넘어가고 있는 이유는 개발자 한 사람이 정해진 구역 만큼만 격리 시켜서 각자 개발자가 서로의 영역을 건드리지 않고 만들고, 각자 만들어 진 것들이 서로 조립해서 하나의 서비스가 된다면 빠르게 만들고(Make fast), 낮은 기술 부채(Low tech debp)를 가지고 나중에 성공했을 때(실패하면 없애버리면 됩니다.)
이 빚을 빨리 없애 버릴 수 있는 그런 구조로 가겠다는 것이 현재의 발전 방향입니다.
이 글들을 통하여 OOP가 절대적인게 아니라는 것을 강조하고 싶습니다. 아직까지는 OOP가 가장 큰 위상을 가지고 있고, OOP를 꼭 알아야 합니다. 우리가 절차적 프로그래밍을 이해해야 OOP를 이해할 수 있고, OOP를 이해해야 우리가 왜 Stateless로 가는지, 왜 필요한 지를 알 수 있죠.
물론 나중에 들어온 사람은 Stateless만 배워도 되겠지만 기존의 흐름을 알아야 더 이해 할 수 있죠.
그리고 기술은 계속 발전하고 있고, 변하고 있다는 것을 알아야 합니다.
나중에 functional language를 배워두면 유익할 것이고, 이렇게 OOP라는 것에 대해 맛만 봤다 생각 하면 됩니다.
'프로그래밍(Basic) > Golang' 카테고리의 다른 글
| Go 1.19 릴리즈 (0) | 2023.05.16 |
|---|---|
| [바미] Go의 signal에 대해 알아봅시다. (0) | 2022.04.11 |
| [바미] Go - ODD의 SOLID에 대해 알아보자. (0) | 2021.03.02 |
| [바미] Go - Interface에 대해 알아보자2. (0) | 2021.03.02 |
| [바미] Go - OOP 3번째! Interface에 대해 알아보자. (0) | 2021.03.02 |